
DocumentDB has since been rebranded/reimagined as CosmosDB and the SDK's have changed as a result. This article is no longer maintained.
Azure DocumentDB is the Platform-as-a-Service NoSQL document database available on Microsoft's cloud platform Azure. Similar to other popular document databases such as MongoDB and RavenDB, DocumentDB allows for the simple storage of entities as JSON with no enforced schema, but with the added benefit of being Platform-as-a-Service. This means that it is completely managed by Azure, with no need to manage the underlying resources and also the ability to use Azure’s impressive scalability at will. DocumentDB is hosted entirely on SSDs and is very fast, with Azure reporting a 1-2ms call completion when working within the same Azure region.
DocumentDB also has the ability to manage transactions, choose consistency levels, to use complex querying with SQL like syntax, and to use server side features, created using JavaScript, in the form of stored procedures, triggers and user defined functions. By default all documents are indexed, however this can be turned off with only document Id’s being indexed.
DocumentDB uses an HTTP API for all functionality and is usable directly, via the Azure portal or using the various SDKs. If you’re already a MongoDB user, you can easily migrate to DocumentDB using its protocol support for MongoDB, allowing you to continue to use the APIs already in use by your existing applications.
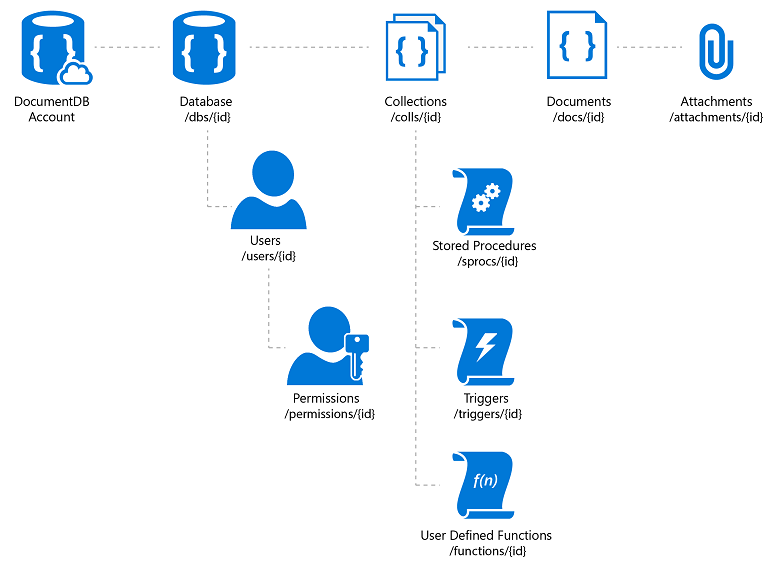
Url structure for DocumentDB resources - source.
This article will explore DocumentDB using the .NET SDK, starting with basic CRUD and then looking at some of the server side functionality.
Using the .NET SDK
Before we get started there is only one prerequisite: you need to have an Azure subscription and a DocumentDB account. If you don’t already have an Azure subscription, then before you go signing up to a pay-as-you-go account and if you are only going to be developing and testing, then let me recommend that you look into Azure credits, specifically the $25 per month you can get for free from Visual Studio Dev Essentials. And whilst you are there, make sure you pick yourself up a 3 month subscription to Pluralsight.
Once you have an Azure account, you can then create a DocumentDB account which requires a unique name, as it provisions a url of accountname.documents.azure.com.
Required nuget package:
install-package Microsoft.Azure.DocumentDB
This will pull down the required dependency of newtonsoft.json.
All interactions with DocumentDB using the .NET SDK use the DocumentClient class.
This is comparable to HttpClient and implements IDisposable in much the same way: designed for reuse across multiple calls to a single resource.
To create a DocumentClient you need your DocumentDB account endpoint and an auth key (full access) or resource token (scoped access).
var client = new DocumentClient(
new Uri("https://accountName.documents.azure.com:443/"), "authKeyOrResourceToken");
The DocumentClient constructor also accepts the key as a SecureString and further parameters such as ConnectionPolicy, which contains things like the retry policy and request timeout, and the ConsistencyLevel.
Initialization
Before we can store documents, we need to create a database and a collection to store them in.
Database
A database is a logical container for your documents and the collections that partition them. It is also the level at which users are stored (users are used to scope access to documents, they are not covered in this tutorial).
You can create a database using the following code:
ResourceResponse<Database> = await client.CreateDatabaseAsync(new Database {Id = "databaseId"});
If successful this will return a ResourceResponse of Database.
Every response from a CRUD request to DocumentDB is wrapped in a ResourceResponse object that contains a unique request Id, various quota/usage data, the returned HTTP status code, the request charge (in request units), and, of course, the resource itself.
If you want to implement create-if-not-exists functionality, you have to do something like the following:
try {
await client.ReadDatabaseAsync(UriFactory.CreateDatabaseUri("databaseId"));
}
catch (DocumentClientException exception) {
if (exception.StatusCode == HttpStatusCode.NotFound) {
await client.CreateDatabaseAsync(new Database {Id = "databaseId"});
}
else {
throw;
}
}
Unfortunately there is no inbuilt functionality for this, so we must take this exception driven approach, looking for a 404 Not Found response from a read request.
You may have noticed in the read request we are using the static UriFactory helper class to create our database URI.
This contains many methods to create the URIs required by the SDK methods, more often than not with the factory method names matching the parameter names you are trying to complete (in this case databaseUri with the matching CreateDatabaseUri).
Collection
A collection is a container for our JSON documents and server side JavaScript logic, with its own performance and partitioning settings. The performance of an individual collection is isolated from all other collections. It is here that we start paying money.
To create a collection you’ll need to do the following:
await client.CreateDocumentCollectionAsync(
UriFactory.CreateDatabaseUri("databaseId"), new DocumentCollection {Id = "collectionId"});This will create a collection with the default values of: single partition mode on the Standard pricing tier with a throughput of 400 RU/s.
We can specify the values we want by passing in some RequestOptions with our CreateDocumentCollectionAsync request, for example:
new RequestOptions {OfferType = "Standard", OfferThroughput = 400}
As with creating a database, in order to create a collection if it does not exist you must use an exception driven approach looking for the 404 response.
The read method we need to fulfil this is ReadDocumentCollectionAsync.
Documents
A document is just JSON, no schema necessary.
All documents must have a unique id property and if one is not assigned then a GUID will be generated for you, however if you want to use an existing property as the Id you can use the JsonPropertyAttribute found in newtonsoft.json.
So let's create a simple entity using that attribute:
private class Post {
[JsonProperty(PropertyName = "id")]
public string Title { get; set; }
public string Category { get; set; }
public List<string> Tags { get; set; }
public DateTime PublishDate { get; set; }
}You can disable automatic Id generation when you go to create a document, causing an exception to be thrown if an Id is missing.
Create
To create a document we call CreateDocumentAsync:
await client.CreateDocumentAsync(
UriFactory.CreateDocumentCollectionUri("databaseId", "collectionId"),
new Post {
Title = "Getting Started with the Azure DocumentDB .NET SDK",
Category = "Azure",
Tags = new List<string> {"Azure", "DocumentDB", "NoSQL"},
PublishDate = new DateTime(2016, 7, 5)
});
The disableAutomaticIdGeneration parameter of this method will prevent automatic Id generation if so desired.
Read Single Document
The fastest way to get a document is to read it by its Id:
var response = await client.ReadDocumentAsync(UriFactory.CreateDocumentUri("databaseId", "collectionId",
"Getting Started with the Azure DocumentDB .NET SDK"));
var post = JsonConvert.DeserializeObject<Post>(response.Resource.ToString());Note that this method requires manual deserialization and will throw an exception if the document does not exist, much like the reading of databases and collections.
Query Documents
To query documents we must use the CreateDocumentQuery or CreateDocumentQuery<T>.
Here we’ll use CreateDocumentQuery<T> as it will allow us to use LINQ easily (we can see the properties). Out of the box CreateDocumentQuery will run synchronously, returning an IQueryable that will run when enumerated:
IQueryable<Post> queryable =
client.CreateDocumentQuery<Post>(UriFactory.CreateDocumentCollectionUri("databaseId", "collectionId"))
.Where(x => x.Category == "Azure");
List<Post> posts = queryable.ToList();The supported LINQ operators of immediate use are:
- Select
- SelectMany
- Where
- OrderBy
- Take
For a full list of supported features see here.
We can also limit the amount of documents returned in our query by supplying some feed options in our request.
new FeedOptions {MaxItemCount = 10}
We can also query documents asynchronously if we use AsDocumentQuery.
This allows for chunking through the use of continuation tokens.
Let's see an example where we iterate through the results using a continuation token:
string continuationToken = null;
do {
var queryable = client.CreateDocumentQuery<Post>(
UriFactory.CreateDocumentCollectionUri("databaseId", "collectionId"),
new FeedOptions { MaxItemCount = 1, RequestContinuation = continuationToken})
.Where(x => x.Category == "Azure")
.AsDocumentQuery();
var feedResponse = await queryable.ExecuteNextAsync<Post>();
continuationToken = feedResponse.ResponseContinuation;
foreach (var post in feedResponse.ToList()) {
Console.WriteLine(post.Title);
}
} while (continuationToken != null);Update
To update a document we can call the ReplaceDocumentAsync method:
await client.ReplaceDocumentAsync(
UriFactory.CreateDocumentUri("databaseId", "collectionId", "Getting Started with the Azure DocumentDB .NET SDK"),
new Post {
Title = "Getting Started with the Azure DocumentDB .NET SDK",
Category = "Azure",
Tags = new List<string> {"Azure", "DocumentDB", "NoSQL", "Updated!"},
PublishDate = new DateTime(2016, 7, 5)
});
This will throw the usual DocumentClientException, with a 404 Not Found, if the document does not exist.
There is a notable overload for the update method, allowing you to pass a Document object you might receive from a dynamic read request, however I find the demonstrated update method the most useful in the typical flow of read and then update.
Upserts are also available, allowing us to forgo the check on whether or not the document exists, inserting it if it doesn't and updating it if it does.
await client.UpsertDocumentAsync(
UriFactory.CreateDocumentCollectionUri("databaseId", "collectionId"),
new Post {
Title = "Getting Started with the Azure DocumentDB .NET SDK",
Category = "Azure",
Tags = new List<string> {" Upserted!"},
PublishDate = new DateTime(2016, 7, 5)
});This method behaves in much the same way as a create method but without the possibility of an Id conflict.
Delete
The delete method should now be pretty obvious to you:
await client.DeleteDocumentAsync(UriFactory.CreateDocumentUri("databaseId", "collectionId", "Getting Started with the Azure DocumentDB .NET SDK"));And that should be plenty to get you started with a DocumentDB repository!
Stored Procedures
Stored Procedues are created using JavaScript, something I don't particularly enjoy or very good at (I go a bit strange when I leave the world of strongly typed languages), so I’m going to give a very basic demonstration of a stored procedure in DocumentDB.
The stored proc:
function(id) {
var context = getContext();
var collection = context.getCollection();
var collectionLink = collection.getSelfLink();
var response = context.getResponse();
var query = 'SELECT * FROM x WHERE x.id = "' + id + '"';
collection.queryDocuments(collectionLink, query, { }, function(err, documents) {
if(!documents || !documents.length) response.setBody('No documents were found.');
else response.setBody(JSON.stringify(documents));
});
}
Here we are simply getting all documents with a specific Id. The getContext method is what allows us to get access to the collection and the response objects, allowing us to create a function that can be run on the server.
To create and invoke the stored procedure we can use the CreateStoredProcedureAsync and ExecuteStoredProcedureAsync methods. See the following example:
const string function = @"function(id) {
var context = getContext();
var collection = context.getCollection();
var collectionLink = collection.getSelfLink();
var response = context.getResponse();
var query = 'SELECT * FROM x WHERE x.id = ""' + id + '""';
collection.queryDocuments(collectionLink, query, { }, function(err, documents) {
if(!documents || !documents.length) response.setBody('No documents were found.');
else response.setBody(JSON.stringify(documents));
});
}";
await client.UpsertStoredProcedureAsync(UriFactory.CreateDocumentCollectionUri(DatabaseId, CollectionId), new StoredProcedure {Id = "TestReadStoredProc", Body = function});
var response = await client.ExecuteStoredProcedureAsync<string>(UriFactory.CreateStoredProcedureUri(DatabaseId, CollectionId, "TestReadStoredProc"), "Getting Started with the Azure DocumentDB .NET SDK");
var posts = JsonConvert.DeserializeObject<List<Post>>(response.Response);What Next?
The server side JavaScript must complete within a time limit, with some operations rolling back and others requiring a continuation based mode.
If you’re going to look at getting serious about performance you’re going to need to dive into the consistency, indexing, partitioning and replication features of DocumentDB in order to tune it to work best for your application. This is where an understanding of the underlying storage concepts is necessary and is well out of the scope of your everyday repository. You can find everything you need to start your journey in the How It Works section of the documentation.
Recommended Pluralsight Course: Introduction to DocumentDB by Leonard Lobel